Analiza eventów, monitory pól
Teraz czas napisać pierwszą analizę. Użyjemy naszego zaawansowanego generatora. Kod główny będzie wyglądał tak:
void glauber_ana() {
auto run = new Hal::AnalysisManager();
auto source = new HalOTF::Source(10000);
auto generator = new CustomGenerator;
TH2D h("spec", "spec", 1, -1, 1, 1, 0, 1);
h.SetBinContent(1, 1, 1);
generator->SetSpiecies(h, Hal::Const::PionPlusPID());
generator->SetFixMult(100);
generator->SetA(197);
source->AddEventGenerator(generator);
// source->Register();
run->SetOutput("/opt/temp/data.root");
run->SetSource(source);
HalOTF::Reader* reader = new HalOTF::Reader();
run->AddTask(reader);
Hal::EventAna* ana = new Hal::EventAna();
ana->SetFormatOption(Hal::EventAna::EFormatOption::kReaderAccess);
Hal::EventFieldMonitorX prop1(Hal::DataFieldID::Event::EMc::kB + Hal::DataFieldID::ImStep);
Hal::EventFieldMonitorX prop2(Hal::DataFieldID::Event::EBasic::kTracksNo + Hal::DataFieldID::ImStep);
prop1.SetXaxis(100, 0, 20);
prop2.SetXaxis(200, 0, 1500);
Hal::EventFieldMonitorXY prop(Hal::DataFieldID::Event::EMc::kB + Hal::DataFieldID::ImStep,
Hal::DataFieldID::Event::EBasic::kTracksNo + Hal::DataFieldID::ImStep);
prop.SetXaxis(100, 0, 20);
prop.SetYaxis(200, 0, 1500);
ana->AddCutMonitor(prop);
ana->AddCutMonitor(prop1);
ana->AddCutMonitor(prop2);
run->AddTask(ana);
run->Init();
run->Run();
}
Nasze makro rozpoczyna się od stworzenia menedżera analizy Hal::AnalysisManager. Następnie tworzymy źródło danych - HalOTF::Source. W liniach 5-9 konfigurujemy nasz generator. Następnie dodajemy go do source.
W linii 15 tworzymy reader. HAL może przetwarzać praktycznie dowolne dane ale musi je sobie tłumaczyć na swój format. Zderzenie przetwarzane przez HAL-a musi dziedziczyc po klasie Hal::Event. Format, który jest produkowany przez nasz generator niestety nie dziedzyczy po tej klasie. Dlatego tworzymy sobie klasę HalOTF::Reader - to specjalna klasa, która konwertuje zderzenia i zapisuje je do branchu "HalEvent.", jeśli naszemu taskowi do analizy nie powiemy jakiego formatu ma używać i w jaki sposób (opcje zaawansowane, rzadziej używane) to taki task poszuka właśnie branchu "HalEvent." i z niego będzie pobierał dane. Ponieważ task powinien widzieć branch już na początku analizy, reader zwykle powinien być pierwszym taskiem w ciągu analiz. Domyślnie dane generowane przez reader są zapisywane w branchu "wirtualnym" tj. takim który jest widoczny podczas analizy, ale nie jest zapisywany w pliku wyjściowym.
Kolejne linie to tworzenie i konfiguracja naszej analizy. Interesują nas analizy zderzeń więc używamy klasy EventAna, robi ona tylko pętle po zderzeniach. W linii 19 konfigurujemy opcję odczytu jako reader - od nowszej wersji (styczeń 2025) ta linia nie jest już potrzebna, gdyż taski domyślnie używają danych z readera.
Następne linie to tworzenie "EventFieldMonitorów" - są to klasy do monitorowania "pól" eventów. Jak nazwa wskazuje zawierają one histogramy z rozkładami wartości "pól" eventów czyli pól z danymi o zderzeniu takich jak np. parametr zderzenia itd. Parametrami konstruktorów są ID pól (Hal::DataFieldID::). W naszym wypadku chcemy zobaczyć rozkład parametru zderzenia, liczby cząstek w zderzeniu oraz korelację obu tych rozkładów.
Gdybyśmy analizowali dane czysto MC (np. z generatora zderzeń typu UrQMD to konstruktory tych klas zawierałyby tylko zmienne typu Hal::DataFieldID::Event::EMc::kB (parametr zderzenia) oraz Hal::DataFieldID::Event::EBasic::kTracksNo (liczba cząstek w zderzeniu). Nasz generator generuje jednak zderzenia w formacie "zespolonym". Format zespolony oznacza, że zderzenie składa się tak naprawdę z trzech zderzeń:
- zderzenie "globalne" (zwykle częściowa kopia zderzenia "rzeczywistego")
- zderzenie "rzeczywiste" zwykle oznaczające zderzenie zrekonstruowane
- zderzenie "urojone" zwykle oznaczające zderzenie symulowane
Jeśli chcemy monitorować część symulowaną (z naszego generatora) to musimy do ID pól dodać Hal::DataFieldID::ImStep, co powoduje odpowiednie przełączenie na właściwy rodzaj danych (tu cześć "urojoną" tj. "symulowaną"). Można zapytać co się stanie jeśli zapomnimy o tym "magicznym" przesunięciu - otóż wtedy HAL spróbuje monitorować po prostu event "globalny" (zwykle właściwości tego zderzenia są kopiowane z części zrekonstruowanej), jeśli dana właściwość będzie dostępna to monitor się przełączy, jeśli nie to po prostu monitor zostanie zablokowany. W naszym przypadku ponieważ zderzenie "globalne" zawiera informację o liczbie cząstek to takie pole by było monitorowane, ale już parametr zderzenia jest cechą jedynie zderzenia symulowanego i taki monitor zwyczajnie by został zablokowany.
Linie 28-30 to dodawanie monitorów pól do analizy. Następnie sama analiza jest dodawana do analysis managera, wywołana zostaje metoda Init i Run która rozpoczyna analizę.
Otwieranie plików
Gdy makro się zakończy możemy zobaczyć, że wygenerowany został pewien plik. Można się do jego zawartości dostać na kilka sposób np. poprzez takie makro:
void glauber_show() {
auto file = new Hal::AnaFile("/opt/temp/data.root");
auto h1 = file->GetHistogramPassed(Hal::ECutUpdate::kEvent, 0, 0);
auto h2 = file->GetHistogramPassed(Hal::ECutUpdate::kEvent, 0, 1);
auto h3 = file->GetHistogramPassed(Hal::ECutUpdate::kEvent, 0, 2);
TCanvas* c = new TCanvas();
c->Divide(2, 2);
c->cd(1);
h1->Draw("colz");
c->cd(2);
h2->Draw();
c->cd(3);
h3->Draw();
}
Funkcja GetHistogramPassed przyjmuje 3 parametry
- pierwszy - flaga określająca rodzaj monitora, np. Hal::ECutUpdate::kEvent oznacza monitor właściwości zderzeń a Hal::ECutUpdate::kTrack monitor właściwości cząstek
- drugi to numer kolekcji, w ty przykładzie istnieje 1 kolekcja więc będzie to zero
- trzeci parametr określa numer monitora jaki się chcę wziąć
Istnieje również funkcja GetHistogramFailed - zwraca ona histogram z danymi, które zostały wyrzucone z analizy.
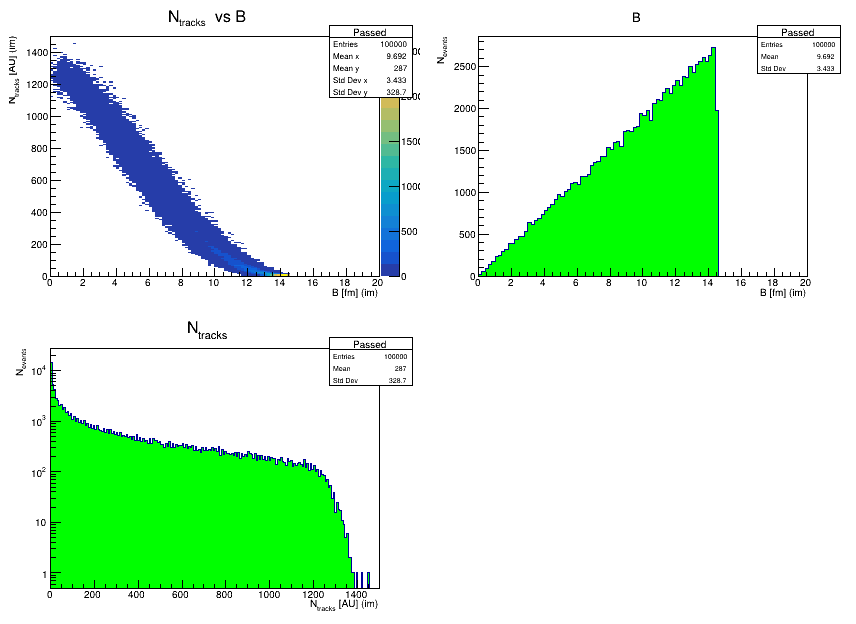
Na histogramie widzimy 3 rozkłady: krotność (liczba cząstek) vs parametr zderzenia, parametr zderzenia oraz krotność. Jak widać parametr zderzenia ma rozkład trójkątny jak chcieliśmy (nawet w zaawansowanych modelach typu UrQMD możemy zobaczyć tego typu rozkład). Pozostałe dwa rozkłady w zasadzie jakościowo również dość dobrze opisują to co otrzymać można z modeli.
Zauważyć możemy tutaj, że grupując dane wg krotności możemy w pewnym stopniu grupować dane wg. parametru zderzenia. Nie jest to jednak ścisła zależność bo nasz "wąż" w rozkładzie krotności vs parametr zderzenia jest dosyć szeroki, oznacza to że nawet wybierając określoną krotność będziemy mieli zawsze kolizje o pewnym rozrzucie parametrów zderzenia. Ale tym zajmiemy się w następnej części tutorialu.